Summary
Setting triggers is one of the cornerstones of the Forecast-based Financing system. For a National Society to have access to automatically released funding for their early actions, their Early Action Protocol needs to clearly define where and when funds will be allocated, and assistance will be provided. In FbF, this is decided according to specific threshold values, so-called triggers, based on weather and climate forecasts, which are defined for each region.
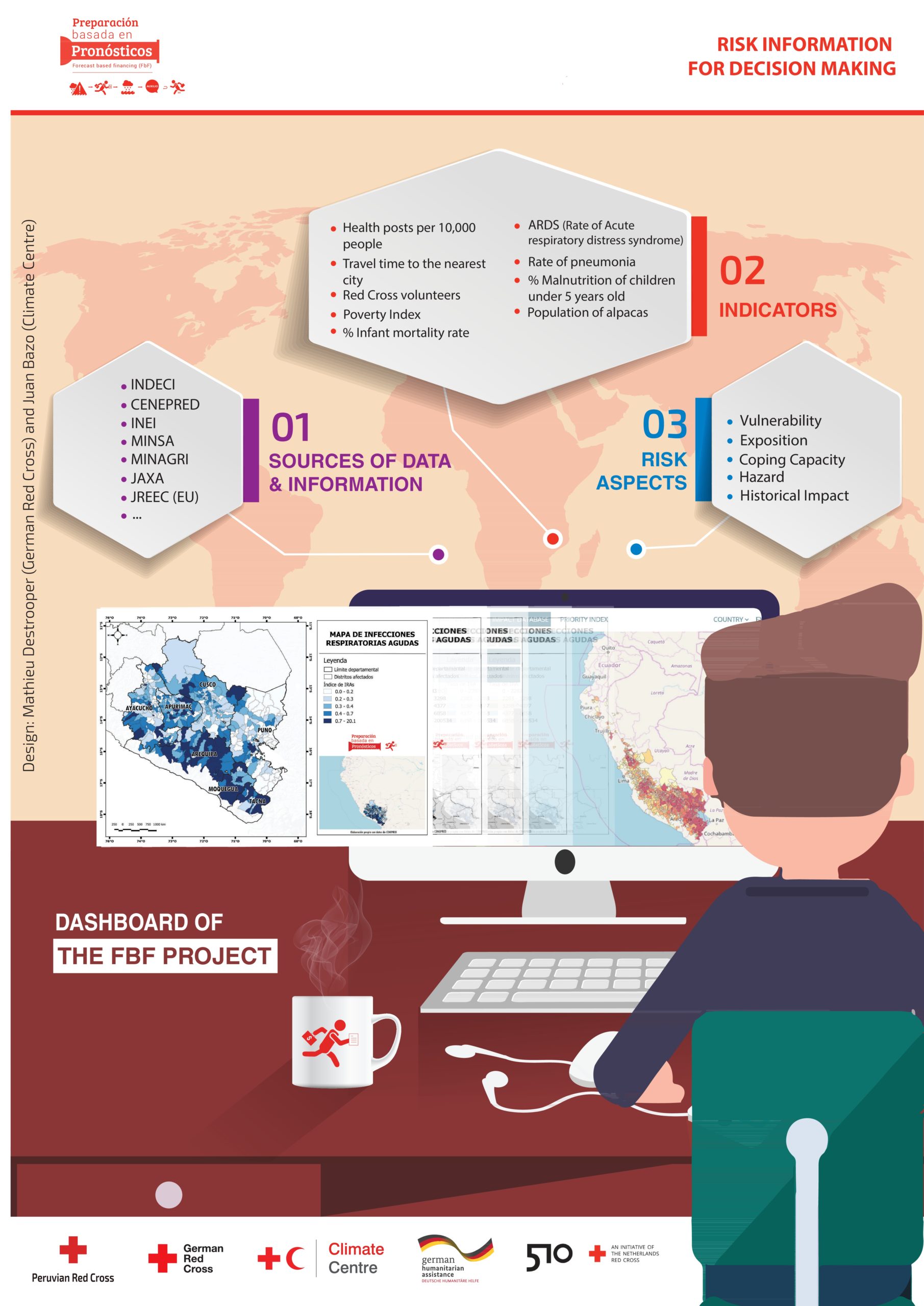
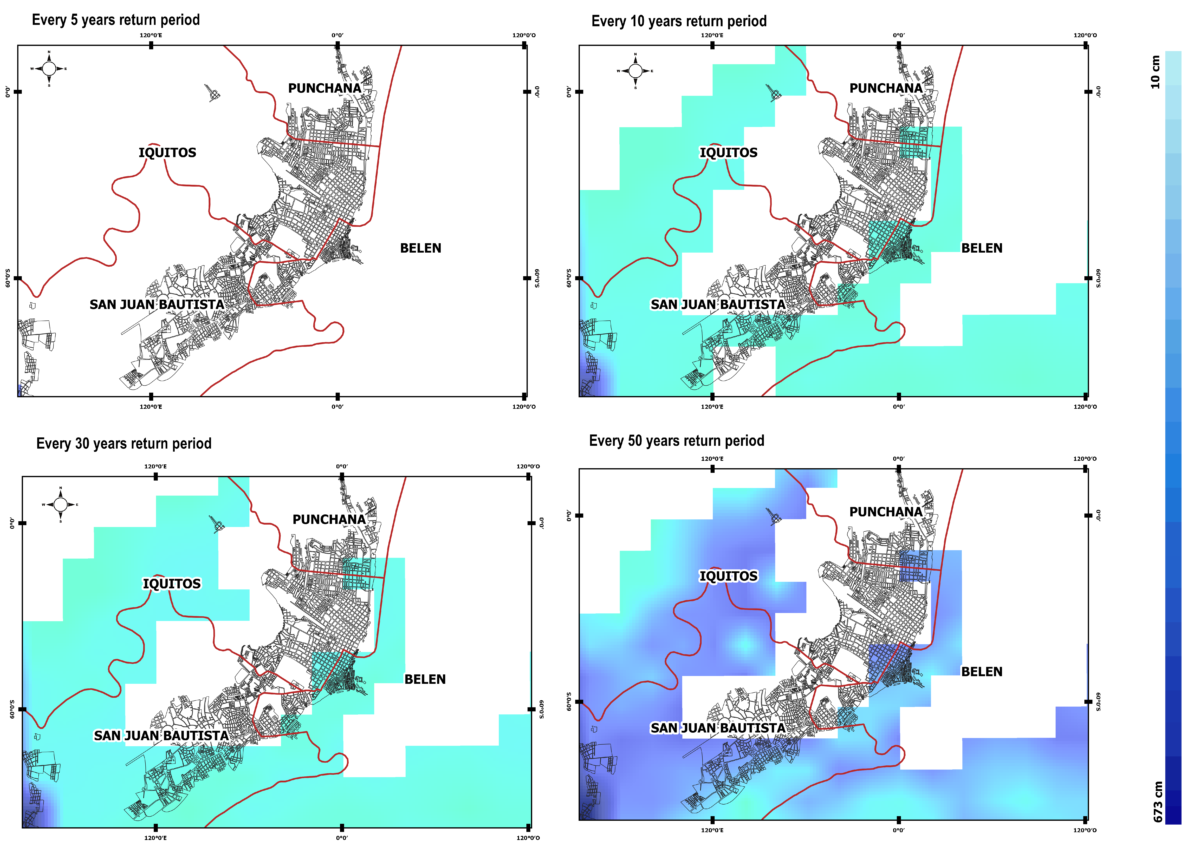
During the last decades, forecasting of climate and weather-related hazards has improved significantly. In parallel to this, our capacity to understand risks has increased, and more data has become available to capture disaster impacts, exposure, and vulnerability. Such developments in hazard-prediction and understanding risk are essential to setting up triggers, which in turn enable decision making and early action before a disaster occurs.
FbF is designed for those weather-events that are predicted to have a severe humanitarian impact, e.g. it is not enough to know what the forecasted windspeed will be, but we need to know whether the storm will cause impact. Thus, in FbF, the trigger is the degree of forecast loss and damage (human, livelihoods, infrastructure, environment etc.), or in other words the degree of humanitarian impact, of an extreme event, that would initiate action. If more than a predetermined probability of a certain amount of loss/damage is forecasted, we act.
For this reason, the Impact-based forecasting approach is the basis of the FbF trigger methodology. It focuses on what the weather will do, rather than forecasting only what the weather be. Ultimately the objective of setting up triggers in the humanitarian and development context is to provide decision makers the necessary information to know when and where early action should take place and who and what is likely to be impacted. In line with the impact-based forecasting approach, the trigger model is developed based on a detailed risk analysis of relevant natural hazards, including impact assessments of past disaster events, and analysis of exposure and vulnerability data.
The work for the identification of triggers can be very technical and require expert resources. Cooperation among key actors and institutions is necessary, including the National Hydrom Meteorological services (NHMS), Disaster Risk Management Agencies (DRM), risk information management experts, and humanitarian and development actors among others. Development of a multi-disciplinary working group is suggested to include all relevant stakeholders. In the case there is a technical lead or advisor for the development of the trigger, specific steps could be researched and written up and the results presented to the working group. The stakeholders in the group can provide occasional feedback to the process and agree on the final recommended triggers (see terms of reference of technical working group).